The new Fujitsu AI Computing Broker Maximizing GPU utilization & minimize the environmental impact of AI

Technology News | 2025-10-09
Enterprises and technology companies are investing at historic levels to support the rapid expansion of artificial intelligence. Hyperscalers alone are expected to spend over $300 billion on AI infrastructure in 2025, and by 2030, large-scale AI systems may consume 10% of the world’s electricity. These figures signal more than just technological progress: They reflect a structural shift in corporate resource allocation as organizations commit capital and energy to computation on a scale comparable to the industrial revolutions of the past.
Yet beneath these headlines lies a paradox. Despite unprecedented investments in GPUs, most enterprises are failing to use them effectively. According to “The State of AI Infrastructure at Scale 2024”, over 75% of organizations report GPU utilization below 70% at peak load. This means that, even as the demand for AI capacity accelerates, the majority of one of the most valuable corporate resources sits idle.
This inefficiency is not a marginal issue. It erodes return on investment, raises infrastructure costs, delays innovation, and inflates the carbon footprint of AI operations. As organizations increasingly define their competitiveness by their ability to build and deploy AI, underutilization has become a silent but systemic threat.
Why utilization, not capacity, defines competitiveness
While the instinctive response to rising AI demand has been to purchase more GPUs, that arms race is proving unsustainable. Supply remains constrained while energy costs escalate, and most enterprises face pressure to achieve ambitious sustainability targets.
The future will belong not to the companies that own the most GPUs, but to those that use them most intelligently. In practice, this means shifting the focus from capacity to utilization. Every percentage point of additional GPU efficiency translates directly into cost savings, faster model development, and more room to experiment with next-generation workloads.
This is especially crucial as AI becomes mission-critical rather than experimental. Drug discovery, supply chain optimization, fraud detection, and customer service personalization all rely on complex pipelines, where the marginal value of each GPU-hour is rising. To remain competitive, enterprises must ensure that GPUs are not only available, but fully and efficiently engaged.
A new model of orchestration
At the root of the underutilization problem is how GPUs are allocated and scheduled. Conventional methods tie GPUs to entire jobs for their full duration, even when workloads alternate between GPU- and CPU-heavy phases. As a result, GPUs often sit idle for long stretches, locked away from other tasks. Attempts to share GPUs through virtualization or partitioning create their own challenges, often limiting memory and blocking larger models from running effectively.
Fujitsu’s AI Computing Broker (ACB) represents a fundamental rethink of this model. Instead of static allocation, ACB employs runtime-aware orchestration, monitoring workloads in real time and dynamically assigning GPUs where they are needed most.
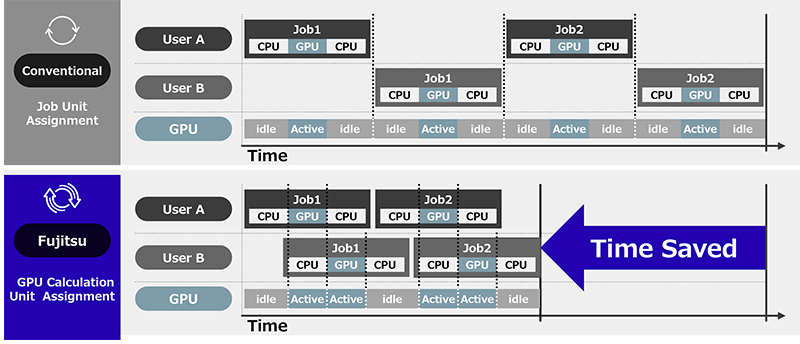
Two components make this possible. The GPU Assigner acts as a central scheduler, applying intelligent policies such as backfilling, which allows smaller jobs to use idle resources while larger tasks are queued. The Adaptive GPU Allocator, a client-side library, manages allocation at the framework level--particularly PyTorch--either automatically by intercepting API calls or manually with explicit developer control. Together, these components create a fluid system where GPUs are continuously rebalanced across tasks, eliminating idle time and unlocking latent capacity.
Unlike traditional approaches, ACB preserves application state during model swaps, avoiding the complexity and overhead of checkpointing. This allows even very large models to run efficiently in shared environments. The result is not only higher utilization, but also greater flexibility in how enterprises deploy and scale their AI workloads.
Efficiency without compromise
Efficiency gains of this magnitude inevitably raise the question of trade-offs. Would dynamic orchestration slow down workloads or undermine performance?
In practice, the opposite has proven true. Consider the case of AlphaFold2, the breakthrough system for protein structure prediction. Its pipeline alternates between CPU-heavy searches and GPU-intensive modeling. In a conventional setup, each job occupies an entire GPU throughout, leading to significant idle time. With ACB, multiple jobs can share a GPU dynamically, filling in the gaps with other tasks. The result: Alphafold2 shows a 270% improvement per GPU. This means that while only 12 proteins could be processed per hour on a single A100, incorporating ACB enabled the processing of 32 proteins per hour.
Similarly, enterprises hosting multiple LLMs face uneven demand. Traditionally, each model is pinned to its own GPU, ensuring responsiveness but wasting capacity when some models sit idle. ACB allows multiple LLMs to dynamically share infrastructure, reclaiming and reallocating memory in real time when demand subsides. Early deployments show that organizations can host significantly more models on the same hardware footprint, reducing costs while maintaining performance.
These examples illustrate a broader truth: While ACB introduces minor overhead from memory transfers, the cluster-level efficiency gains far outweigh the cost. At the scale where enterprises operate, the key metric is not the speed of a single job but the overall throughput of the system. On this measure, ACB consistently delivers transformative improvements.
Strategic implications for leaders
For business and technology leaders, the implications are profound.
First, ACB changes the economics of scale. By allowing enterprises to run more workloads on fewer GPUs, it reduces reliance on capital-intensive hardware purchases. In a market where GPU supply is scarce and prices volatile, this creates both a financial buffer and strategic resilience.
Second, the technology accelerates innovation cycles. Faster throughput translates into faster iteration, which in turn fuels more rapid discovery and deployment. Whether testing new drug candidates, refining risk models, or developing new customer experiences, speed compounds advantage.
Third, ACB supports sustainability goals. If AI infrastructure is destined to be a major consumer of electricity, then efficiency is not optional—it is an imperative. By consolidating workloads, enterprises can shrink their energy footprint and align AI growth with environmental commitments.
Seen through this lens, ACB is not just a tool for efficiency but a lever for competitiveness, enabling organizations to pursue ambitious AI strategies without being constrained by the limits of static infrastructure.
Adoption Without Disruption
A common barrier to infrastructure optimization is the fear of disruption. Enterprises often hesitate to re-engineer mission-critical systems. Fujitsu has designed ACB with this concern in mind.
For most PyTorch-based workloads, ACB can be deployed as a drop-in solution, with no code modifications required. The Adaptive GPU Allocator automatically intercepts GPU activity, allowing enterprises to see results almost immediately. For teams that require precise control, lightweight APIs enable manual integration, but even this is minimal in scope.
Deployment is equally flexible. ACB runs on bare metal, within Docker containers, and integrates with schedulers like Slurm, allowing enterprises to start small pilots on a single node before scaling to full production environments. Future releases will extend the range of deployment options.
Proof points across industries
The benefits of ACB are not theoretical. Its impacts are already being demonstrated in early deployments across industries.
In life sciences, AlphaFold2 pipelines have achieved dramatic throughput improvements, enabling larger molecular libraries to be screened with fewer GPUs. In financial services, risk models are trained more efficiently, accelerating decision-making in volatile markets. In retail, AI-powered vision systems for stores have scaled more effectively, improving security and customer analytics without additional hardware. And in cloud services, providers have been able to expand GPU access for customers without expanding their physical footprints.
Across these domains, a consistent pattern emerges: ACB helps organizations unlock the hidden potential of the infrastructure they already own, extending the life of capital investments and enabling innovation that would otherwise be cost-prohibitive.
From optimization to transformation
What makes Fujitsu’s AI Computing Broker so compelling is that it represents more than just an optimization. It signals a new paradigm for how enterprises think about compute resources.
In the old model, infrastructure was static and scarce, and success was defined by capacity ownership. In the emerging model, infrastructure is dynamic and fluid, with success defined by effective resource orchestration.
This transformation mirrors other moments in technology history, from the shift to virtualization in servers to the rise of cloud-native architectures. Each time, organizations that embraced dynamic resource management were able to outpace competitors who remained bound by static models. The same will be true in AI.
Is the Fujitsu AI Computing Broker right for you?
Organizations that meet the criteria below may stand to benefit most from ACB.
-
Alternating workloads:
Your processes involve phases that switch between CPU and GPU tasks, requiring dynamic resource allocation.
-
Multiple job management:
You have several GPU-capable tasks that can be efficiently queued or batched to optimize resource use.
-
Intermittent full memory utilization:
Your workloads occasionally demand full GPU memory, benefiting from flexible memory access.
-
Multi-LLM hosting needs:
You need to manage multiple domain-specific LLMs with varying demand on shared GPU infrastructure, ensuring efficient resource distribution.
Your opportunity to experience the Fujitsu AI Computing Broker
Fujitsu is excited to offer you free, no-commitment early access to the Fujitsu AI Computing Broker. This is your chance to experience firsthand the remarkable performance, flexibility, and control that this cutting-edge solution provides. Explore its key features, designed to transform your AI infrastructure:
-
Runtime-Aware GPU allocation:
Dynamically adjusts GPU resources by continuously monitoring AI frameworks, ensuring optimal utilization and efficiency.
-
Full memory access:
Grants active programs complete access to GPU memory, enhancing computational power and performance.
-
Advanced scheduling:
Employs sophisticated techniques like backfill to optimize job placement, maximizing overall GPU usage and throughput.
-
Effortless deployment:
Seamlessly integrates into your existing systems without the need for code modifications, facilitating quick and straightforward adoption.
Discover how the Fujitsu AI Computing Broker can revolutionize your AI operations, driving greater efficiency and fostering innovation. Don't miss this opportunity to elevate your AI capabilities and stay ahead in the competitive landscape.
Conclusion
Every organization faces a choice. On one path lies escalating infrastructure spend, increasing dependence on constrained supply chains, and rising energy costs. On the other lies a smarter approach: extracting full value from existing assets, scaling more intelligently, and turning efficiency into competitive advantage.
Fujitsu’s AI Computing Broker offers a way forward. It does not ask enterprises to choose between ambition and efficiency but enables them to pursue both. By integrating ACB into existing stacks, organizations can begin reclaiming idle capacity within days, turning underutilization from a hidden tax into a strategic advantage.
In the race to scale AI, the winners will not be those who merely acquire the most GPUs. They will be those who orchestrate them best.
Why not experience the benefits of Fujitsu’s AI Computing Broker yourself by taking advantage of our free, 30-day, no commitment Early Access Program?
Nick Cowell
Principal Consultant & Fujitsu Distinguished Engineer, Technology Strategy Unit, Fujitsu
Nick is a technologist and futurist with extensive experience in hardware, software, and service development, having previously worked for leading technology providers across the USA, Europe, and Oceania.

Unlock free early access and learn more about Fujitsu AI Computing Broker here.

Related Information
Addressing AI's Power Consumption Challenges Fujitsu's Three Energy-Saving Technologies

Confronting GPU Shortages head on: The dynamics behind the development of the AI computing broker
